2015/10/19
- 前回のレポートで、"対象データについては「1byte系」で構成されたものに限定" としましたが、今回のレポートでは2byte系データ/日本語データに話を移したいと思います。今回はテスト用として、下記のようなデータを用意しました。

test.xls / test.xlsx とも同じデータです - 上記のExcelデータを例えば下記のコード(ParseExcel版)で読み込むとします。(前回のレポートと同じコードです)
List1. test.xlsをParseExcelで読む#!/usr/bin/perl -w use Spreadsheet::ParseExcel; use strict; { my $FileName = 'test.xls'; # テスト用Excel(xls)ファイル名 my $ExcelObj = Spreadsheet::ParseExcel->new(); # ParseExcelのオブジェクト定義 my $Book = $ExcelObj->parse($FileName); # xlsファイル読み込み/book扱い for my $Sheet ($Book->worksheets()) { # worksheetオブジェクト取得 &GetValuesFromSheet($Sheet); # worksheetデータ取得へ } } sub GetValuesFromSheet { # wroksheetデータ取得 my ($Sheet) = @_; print "Sheet name : ",$Sheet->get_name(),"\n"; # worksheet名表示 my ($Rmin, $Rmax) = $Sheet->row_range(); # 行のデータ範囲(最小,最大) my ($Cmin, $Cmax) = $Sheet->col_range(); # 列のデータ範囲(最小,最大) for (my $row=$Rmin; $row<=$Rmax; $row++) { # rowは行番号 for (my $col=$Cmin; $col<=$Cmax; $col++) { # colは列番号 my $Cell = $Sheet->get_cell($row,$col); # Cellオブジェクト取得 if (defined($Cell)) { print " CellValue[$row,$col] = ",$Cell->value(),"\n"; # 値の取得/表示 } else { print " CellValue[$row,$col] = undefined\n"; } } } } - 上記のスクリプトを実行すると、Windowsのコマンドプロンプト上では、下記の残念な結果が得られます。日本語データ部が全て文字化けしています。
List2. ParseExcelの出力をそのままコマンドプロンプトへSheet name : Sheet1 Wide character in print at test_xls_pre.pl line 28. CellValue[0,0] = 譌・譛ャ隱・ Wide character in print at test_xls_pre.pl line 28. :(中略) Wide character in print at test_xls_pre.pl line 28. CellValue[4,0] = 繝九・繝ウ繧エ CellValue[5,0] = Hello! Wide character in print at test_xls_pre.pl line 28. CellValue[6,0] = 螟門嵜隱・ Wide character in print at test_xls_pre.pl line 28. CellValue[7,0] = 螟門嵜隱槭〒縺・
-
結論から書くと、コードの一部を青字部のように修正すれば、Shift_JIS文字コードとして日本語データ出力できます。
Lits3. スクリプトを一部修正#!/usr/bin/perl -w use Spreadsheet::ParseExcel; use Encode; use strict; { :(中略) } sub GetValuesFromSheet { # wroksheetデータ取得 :(中略) if (defined($Cell)) { print " CellValue[$row,$col] = ", Encode::encode('Shift_JIS', $Cell->value()),"\n"; # 値の取得/表示 } else { :(中略) }
下記が出力結果です。(test.xlsをParseExcelで読んだ結果です)
List4. 修正後スクリプトの出力結果Sheet name : Sheet1 CellValue[0,0] = 日本語 CellValue[1,0] = 日本語です CellValue[2,0] = 日本語にほんご CellValue[3,0] = 日本語ニホンゴ CellValue[4,0] = ニホンゴ CellValue[5,0] = Hello! CellValue[6,0] = 外国語 CellValue[7,0] = 外国語です
- ああ、つまりUTFのデータをShift_JISに変換すれば良いんだね、のように見えると思いますが、ここはもう少し真面目な理解が必要です。ここはもう少し真面目な理解が必要です。大事なことなので二回書きました。
デコードフラグ付きUnidodeデータ
- 通常日本語Windows上でPerlスクリプトをエディタにより作成すると、その日本語コードはShift_JISになっていると思います。またコマンドプロンプトの日本語コードは言うまでも無くShift_JISです。これから推測できるようにParseExcel及びParseXLSXの出力結果は、Shift_JISではなく、実はUTF-8です。
- Perlの場合、特にUTF-8については「内部文字列」(*1)と呼ばれているものがあります。これは別名「デコードフラグ付きUTF-8」とも呼ばれます。この文字列データとPerlのEncodeモジュールが持つ関数との関係を図に示したものが下記です。
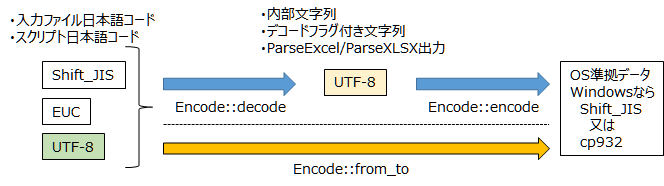
Figure1. Encodeモジュール関数と文字列データの関係
- List3. では、ParseExcelの日本語データ出力を、Windowsのコマンドプロンプトへ表示するために、Encode::encode関数を使用しました。そうです。ParseExcel及びPareseXLSXの出力は「デコードフラグ付きUTF-8」なのです。この理解が浅い状態で闇雲にEncodeの関数を使用すると泥沼にはまるので注意して下さい。
しかしParseXLSXの出力は...
- 日本語文字コードの処理についてすっきりしたところで、ParseXLSXも全く同様にEncode::encode('Shift_JIS',...)を経由して出力してみます。すると、文字化けはしないのですが、余計な文字がくっついてきます...何だこれ...読み仮名?(*2)
List5. ParseXLSXでの出力結果...あれ?...Sheet name : Sheet1 CellValue[0,0] = 日本語ニホンゴ CellValue[1,0] = 日本語ですニホンゴ CellValue[2,0] = 日本語にほんごニホンゴ CellValue[3,0] = 日本語ニホンゴニホンゴ CellValue[4,0] = ニホンゴ CellValue[5,0] = Hello! CellValue[6,0] = 外国語ガイコクゴ CellValue[7,0] = 外国語ですガイコクゴ
- 結局この原因を探るために、xlsxファイルの該当部データ構造を見ることにしました。Excelのxlsxデータは、複数のXMLデータをzipで書庫化したものです。なので拡張子をzipに変えてしまえば解凍ツールで中身を見ることができます。これも結論から書くと、セルに置かれているデータは xl/sharedStrings.xml の中に記述(*3)されています。
List6. sharedStrings.xmlの内容。少し整形している。<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <sst xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" count="7" uniqueCount="7"> <si><t>日本語</t><rPh sb="0" eb="3"><t>ニホンゴ</t></rPh><phoneticPr fontId="2"/></si> <si><t>日本語です</t><rPh sb="0" eb="3"><t>ニホンゴ</t></rPh><phoneticPr fontId="2"/></si> <si><t>日本語にほんご</t><rPh sb="0" eb="3"><t>ニホンゴ</t></rPh><phoneticPr fontId="2"/></si> <si><t>日本語ニホンゴ</t><rPh sb="0" eb="3"><t>ニホンゴ</t></rPh><phoneticPr fontId="2"/></si> <si><t>外国語</t><rPh sb="0" eb="3"><t>ガイコクゴ</t></rPh><phoneticPr fontId="2"/></si> <si><t>外国語です</t><rPh sb="0" eb="3"><t>ガイコクゴ</t></rPh><phoneticPr fontId="2"/></si> <si><t>Hello!</t><phoneticPr fontId="2"/></si> </sst>
- 恐らくですが、これを見ると<si>〜</si>に囲まれた部分がセルのデータで、<rPh>〜</rPh>の中で<t>〜</t>のデータが読み仮名として入っており、このParseに失敗している模様です。とりあえず、これで幾つか解析のヒントとなるキーワードが拾えました。
- shared string : ファイル名(sharedStrings.xml)から
- si : セルのデータ<si>から
- t : データの本体及び仮名データ<t>から
- rPh : 仮名データを囲む<rPh>から
ParseXLSXを少しだけ解析
- とりあえず、どんな名前の関数を持っているか探すと下記の結果になりました。ちなみにParseXLSXのVersionは「0.17」です。
List7. ParseXLSX.pmのsubroutineチェック結果(中略してますが、全部でも30行程度)>find /I /N "sub " ParseXLSX.pm ---------- PARSEXLSX.PM [17]sub new { [22]sub parse { [46]sub _parse_workbook { [108]sub _parse_sheet { : (中略) [370]sub _parse_shared_strings { ← キーワードが多い... [379] 'si' => sub { ← これもキーワードで行が近い... [395]sub _parse_themes { [415]sub _parse_styles { : (中略) - こんなとりあえずチェックでも結構引っかかるものだなと思いつつ、まずは _parse_shared_strings 関数を見ることにしました。この関数も大きくなかったため、リストに示します。
List8. _parse_shared_strings 関数 (青字部はAltmo追加コメント)sub _parse_shared_strings { my $self = shift; my ($strings) = @_; my $PkgStr = []; if ($strings) { my $xml = XML::Twig->new( twig_handlers => { 'si' => sub { # si(Cellデータ)へのハンドラ定義 my ( $twig, $si ) = @_; # XXX this discards information about formatting within cells # not sure how to represent that push @$PkgStr, join( '', map { $_->text } $si->find_nodes('.//t') ); # <t>文字列</t>連結 $twig->purge; }, } ); $xml->parse( $strings ); } return $PkgStr; } - いきなりですがビンゴのようです。恐らく $si->find_nodes('.//t')が、<t>〜</t>で囲まれた文字列をリストとして返し、それをjoinで連結しています。先ほどXMLを見たように、<si>〜</si>の中には複数の<t>〜</t>があるため、データ本体と読み仮名が連結されたデータとして出力されるわけです。バグポイントらしきところは判明したので今度はこれを修正してみましょう。
ParseXLSXの修正
- 修正の方針としては、読み仮名のデータが<rPh>〜</rPh>に記述されていることはわかっているので、これらのテキストデータを抽出した後、空文字列に変更しようと思います(*4)。この方針で修正してみたところうまくいきました。下記リストに示します。
List9. _parse_shared_strings 関数修正版 (青字部は修正部)sub _parse_shared_strings { my $self = shift; my ($strings) = @_; my $PkgStr = []; if ($strings) { my $xml = XML::Twig->new( twig_handlers => { 'si' => sub { my ( $twig, $si ) = @_; # 仮名文字列抽出 my @list_phonetic = map({$_->text} $si->find_nodes('.//rPh')); if ($#list_phonetic >= 0) { # 仮名文字含むケース # 文字列データ抽出:文字列データ本体と仮名文字列が混ざっている my @list_sitext = map({$_->text} $si->find_nodes('.//t')); for (my $i=0; $i<@list_sitext; $i++) { for (my $j=0; $j<@list_phonetic; $j++) { # 文字列データが仮名文字列と「完全に」同じなら消す if ($list_sitext[$i] eq $list_phonetic[$j]) { $list_sitext[$i] = ''; last; } } # for $j } # for $i push(@{$PkgStr}, join('', @list_sitext)); } else { # 仮名文字含まないケース(従来) # XXX this discards information about formatting within cells # not sure how to represent that push @$PkgStr, join( '', map { $_->text } $si->find_nodes('.//t') ); } $twig->purge; }, } ); $xml->parse( $strings ); } return $PkgStr; } - ParseXLSXの記述修正後、Excelファイル(test.xlsx)を読み込んだ結果です。文字列データの本体だけ取り出せていることがわかります。
List10. ParseXLSX修正後のExcel(test.xlsx)読込結果Sheet name : Sheet1 CellValue[0,0] = 日本語 CellValue[1,0] = 日本語です CellValue[2,0] = 日本語にほんご CellValue[3,0] = 日本語ニホンゴ CellValue[4,0] = ニホンゴ CellValue[5,0] = Hello! CellValue[6,0] = 外国語 CellValue[7,0] = 外国語です
- 非常にやっつけ感はありますが、原因と対策は取れそうなので、Moduleが修正されるまでは、これで凌ごうと思います。
- 「あれ? use utf8; は?」と思われる方いると思いますが、敢えて記述を避けています。use utf8;を使うよりも、外部ファイルの文字コードとコンソールの文字コードを了解したうえでコードを組む方が柔軟性を出しやすいと考えているからです。我々にとってはマルチバイトの環境こそがメジャーなので。
- 前回のレポート記述時はここで止まってしまい、とりあえず1byte限定でネタを書きました。
- ファイル数はそんなに多くないので、数ファイルをチラ見する程度ですぐにわかります。
- 実装は人それぞれだと思います。ちなみに私はソフトのエンジニアではありません。
Copyright(C) 2015 Altmo
本HPについて
本HPについて