2021/04/04
- 今に始まったことではありませんが、プログラミング入門本は、大体下記のような内容だったりします。
- Hello World!(*1)
- 変数とデータ型
- 条件分岐
- 繰り返し
- 関数
- 最後の"関数"の扱いが怪しいとしても、上記内容で簡単なプログラミングができるようになります。ちょっとした処理ならこれでも十分です。簡単な内容だったとしても、正確で高速、そして再現性(*2)のある手段を持つことは、仕事/作業の効率を格段に向上させます。
- ですが、関数の使い方...構造化が怪しい状態では、組み合わせによる複雑な処理の実現ができません。結果として「まぁ表計算ソフトで良いか」となって、プログラミングのメリットを感じられないという状況になりがちです。
- あともう一点。我々がプログラミングを行う内容の多くは "なにかの文字列を処理する" ものがほとんどです。しかし文字列の処理...探す/抜き出す/置換する...といった処理は "一から作ると(*3)" 非常に難しく、実行できるイメージが湧きません。
- 結果としてプログラミング入門本で勉強したものの、やりたいことを実現できないため、使わなくなってしまうのです。
中級プログラマへの道、それは参照と正規表現
- なので「人に使わせるわけではないが、自分がやりたいことを実現できる」レベルを中級プログラマ(*4)と定義すれば、私が考える「中級プログラマに必要な知識」とは、下記二点です。
- 参照(reference)
- 正規表現(regular expression)
- 参照と正規表現の知識が必要な理由について、それぞれ説明します。
参照(reference)の知識が必要な理由
- プログラムにおいて複雑な処理は単純な処理の組み合わせで実現します。イメージとしては、パワーポイント等のプレゼンソフトで複雑な平面図形を描くとき、○と△と□を組み合わせるのと同じです。その処理分割を実現するために関数を使うのですが、恐らく「そんなことはわかっている。だがうまく使えない」というモヤモヤした思いを持っているのではないでしょうか。
- 実はこれ、入門本の書き方が悪いのです。入門本内では短いコードしか掲載できないので、関数で扱っているデータはシンプルなものです。その結果データの構造化については全く触れられていないことがほとんどです。
- 一部例外を除き、多くの「複雑な処理」とは、データを集め、分類/関連付けを行い、必要な形に整形/抽出することです。その処理に従って必然的にデータも構造を持つことになりますが、この説明がほとんどされていません。結果として処理の分割はできても、処理結果をデータに反映させることができず、受け渡しに困って関数分割ができなくなります。
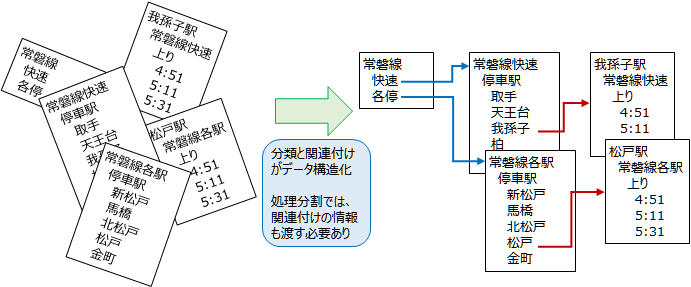
Figure 1: 処理されたデータは構造をを持つ - このデータの構造化を実現するために必要な知識が参照(reference)なのです。本レポートではサンプルコードにPerlを使う予定ですが、Perlの参照は記述自由度が高くとても使いやすいです。
正規表現(regular expression)の知識が必要な理由
- 先程も書きましたが、我々の扱うデータの多くは「何かしらの文字/数字データ」です。それらから必要な情報を抜き出し/加工します。
- 例えば下記のデータ(test.txt)から、青字部分を取り出したいとしましょう。
input clk; // clock output monitor ; input reset ; // async reset // bus inout [7:0] data;
- 普通に考えると結構面倒です。キーワードとなるinput/output/inoutの後、;までの文字列ですが、タブを含んだ何文字かのスペースを挟んでいたりします。この面倒さ故に「データのフォーマットを決めて、なるべくCSVにして」等の話が出てきたりしますが、実は正規表現(regular expression)を使ってパターンマッチングさせると解決できるケースが増えます。
- 今回の例だと青字部分は、正規表現を利用すると下記のように表現できます。括弧()で囲まれている ".+" 部がマッチ部分のキャプチャ対象になります。 ^\s*\w+ut\s+(.+)\s*;
- 実際にPerlのコードにすると、下記のようになります。かなりシンプルになりますね。
[Perl コード: test.pl] #!/usr/bin/perl -w use strict; { my @src = <>; for (my $i=0; $i<@src; $i++) { if ($src[$i] =~ /^\s*\w+ut\s+(.+)\s*;/) { print $1,"\n"; } } }
[出力結果] > test.pl < test.txt clk monitor reset [7:0] data - このように「一見単純だけど少し面倒な処理」が簡単にできるようになると、プログラミングが使いやすくなるため適用/利用機会が増えていき、慣れることで更に使いやすくなるという正のループに入ります。
次回は参照について具体的な話を
- 今回のレポートだけでは、まだ漠然とした感じがあると思います。次回より参照について話をします。データ構造化の具体例を見てもらい「これは使えるかな」と考えてもらう「きっかけ」を目指します。
Copyright(C) 2021 Altmo
本HPについて
本HPについて